

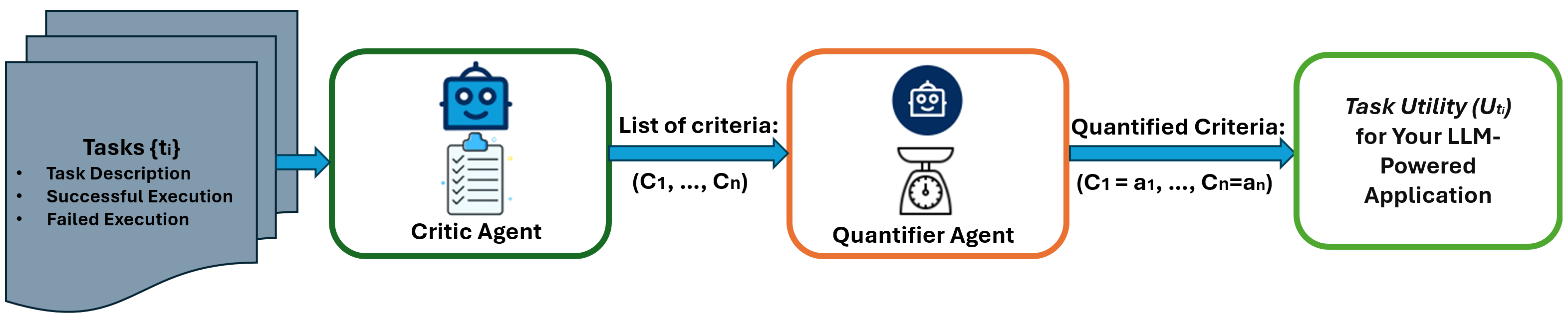
Fig.1 illustrates the general flow of AgentEval
TL;DR:
- As a developer of an LLM-powered application, how can you assess the utility it brings to end users while helping them with their tasks?
- To shed light on the question above, we introduce
AgentEval— the first version of the framework to assess the utility of any LLM-powered application crafted to assist users in specific tasks. AgentEval aims to simplify the evaluation process by automatically proposing a set of criteria tailored to the unique purpose of your application. This allows for a comprehensive assessment, quantifying the utility of your application against the suggested criteria. - We demonstrate how
AgentEvalwork using math problems dataset as an example in the following notebook. Any feedback would be useful for future development. Please contact us on our Discord.
Introduction
AutoGen aims to simplify the development of LLM-powered multi-agent systems for various applications, ultimately making end users' lives easier by assisting with their tasks. Next, we all yearn to understand how our developed systems perform, their utility for users, and, perhaps most crucially, how we can enhance them. Directly evaluating multi-agent systems poses challenges as current approaches predominantly rely on success metrics – essentially, whether the agent accomplishes tasks. However, comprehending user interaction with a system involves far more than success alone. Take math problems, for instance; it's not merely about the agent solving the problem. Equally significant is its ability to convey solutions based on various criteria, including completeness, conciseness, and the clarity of the provided explanation. Furthermore, success isn't always clearly defined for every task.
Rapid advances in LLMs and multi-agent systems have brought forth many emerging capabilities that we're keen on translating into tangible utilities for end users. We introduce the first version of AgentEval framework - a tool crafted to empower developers in swiftly gauging the utility of LLM-powered applications designed to help end users accomplish the desired task.
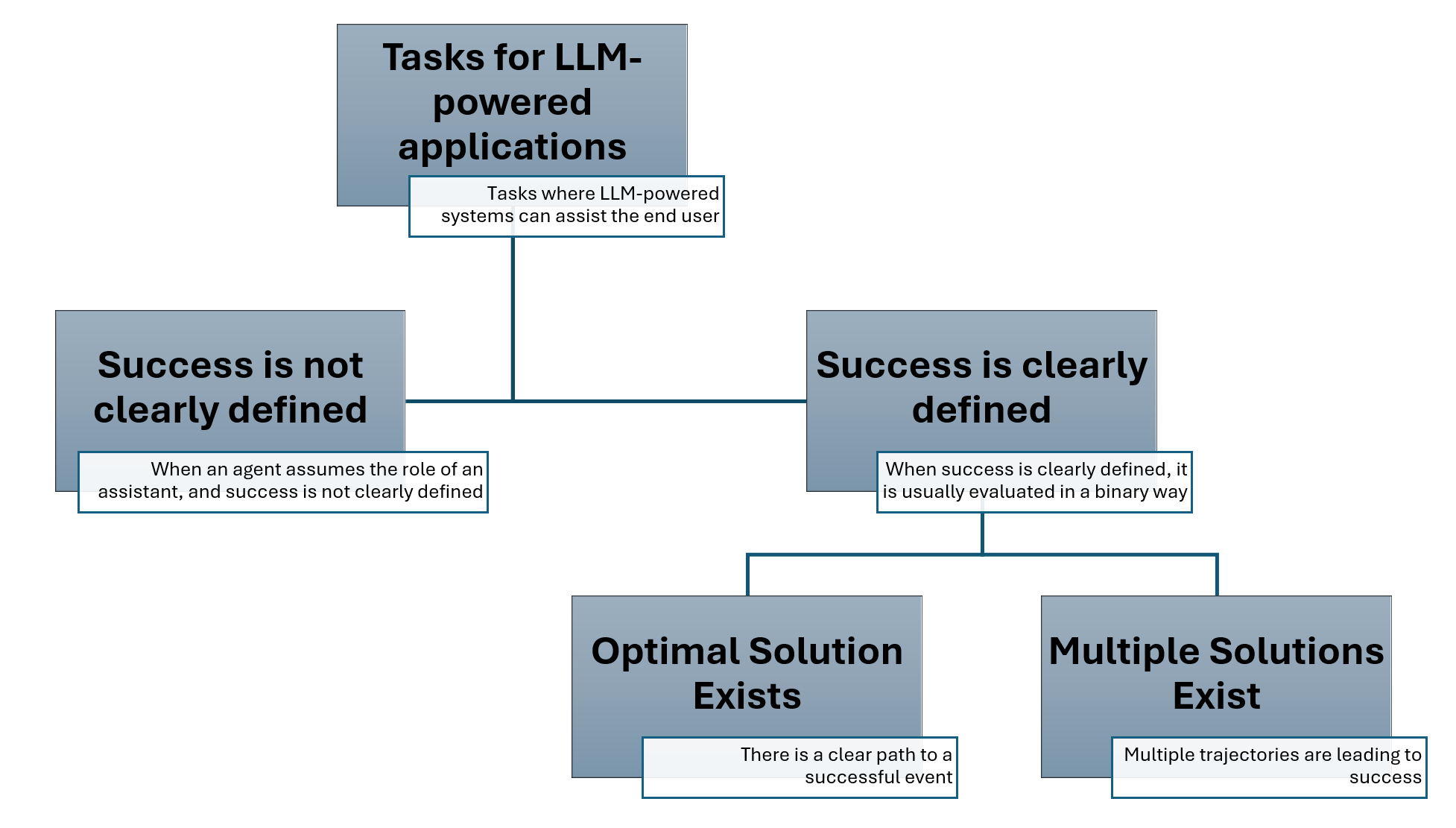
Fig. 2 provides an overview of the tasks taxonomy
Let's first look into an overview of the suggested task taxonomy that a multi-agent system can be designed for. In general, the tasks can be split into two types, where:
- Success is not clearly defined - refer to instances when users utilize a system in an assistive manner, seeking suggestions rather than expecting the system to solve the task. For example, a user might request the system to generate an email. In many cases, this generated content serves as a template that the user will later edit. However, defining success precisely for such tasks is relatively complex.
- Success is clearly defined - refer to instances where we can clearly define whether a system solved the task or not. Consider agents that assist in accomplishing household tasks, where the definition of success is clear and measurable. This category can be further divided into two separate subcategories:
- The optimal solution exits - these are tasks where only one solution is possible. For example, if you ask your assistant to turn on the light, the success of this task is clearly defined, and there is only one way to accomplish it.
- Multiple solutions exist - increasingly, we observe situations where multiple trajectories of agent behavior can lead to either success or failure. In such cases, it is crucial to differentiate between the various successful and unsuccessful trajectories. For example, when you ask the agent to suggest you a food recipe or tell you a joke.
In our AgentEval framework, we are currently focusing on tasks where Success is clearly defined. Next, we will introduce the suggested framework.
AgentEval Framework
Our previous research on assistive agents in Minecraft suggested that the most optimal way to obtain human judgments is to present humans with two agents side by side and ask for preferences. In this setup of pairwise comparison, humans can develop criteria to explain why they prefer the behavior of one agent over another. For instance, 'the first agent was faster in execution,' or 'the second agent moves more naturally.' So, the comparative nature led humans to come up with a list of criteria that helps to infer the utility of the task. With this idea in mind, we designed AgentEval (shown in Fig. 1), where we employ LLMs to help us understand, verify, and assess task utility for the multi-agent system. Namely:
- The goal of
CriticAgentis to suggest the list of criteria (Fig. 1), that can be used to assess task utility. This is an example of howCriticAgentis defined usingAutogen:
critic = autogen.AssistantAgent(
name="critic",
llm_config={"config_list": config_list},
system_message="""You are a helpful assistant. You suggest criteria for evaluating different tasks. They should be distinguishable, quantifiable, and not redundant.
Convert the evaluation criteria into a dictionary where the keys are the criteria.
The value of each key is a dictionary as follows {"description": criteria description, "accepted_values": possible accepted inputs for this key}
Make sure the keys are criteria for assessing the given task. "accepted_values" include the acceptable inputs for each key that are fine-grained and preferably multi-graded levels. "description" includes the criterion description.
Return only the dictionary."""
)
Next, the critic is given successful and failed examples of the task execution; then, it is able to return a list of criteria (Fig. 1). For reference, use the following notebook.
- The goal of
QuantifierAgentis to quantify each of the suggested criteria (Fig. 1), providing us with an idea of the utility of this system for the given task. Here is an example of how it can be defined:
quantifier = autogen.AssistantAgent(
name="quantifier",
llm_config={"config_list": config_list},
system_message = """You are a helpful assistant. You quantify the output of different tasks based on the given criteria.
The criterion is given in a dictionary format where each key is a distinct criteria.
The value of each key is a dictionary as follows {"description": criteria description , "accepted_values": possible accepted inputs for this key}
You are going to quantify each of the criteria for a given task based on the task description.
Return a dictionary where the keys are the criteria and the values are the assessed performance based on accepted values for each criteria.
Return only the dictionary."""
)
AgentEval Results based on Math Problems Dataset
As an example, after running CriticAgent, we obtained the following criteria to verify the results for math problem dataset:
| Criteria | Description | Accepted Values |
|---|---|---|
| Problem Interpretation | Ability to correctly interpret the problem | ["completely off", "slightly relevant", "relevant", "mostly accurate", "completely accurate"] |
| Mathematical Methodology | Adequacy of the chosen mathematical or algorithmic methodology for the question | ["inappropriate", "barely adequate", "adequate", "mostly effective", "completely effective"] |
| Calculation Correctness | Accuracy of calculations made and solutions given | ["completely incorrect", "mostly incorrect", "neither", "mostly correct", "completely correct"] |
| Explanation Clarity | Clarity and comprehensibility of explanations, including language use and structure | ["not at all clear", "slightly clear", "moderately clear", "very clear", "completely clear"] |
| Code Efficiency | Quality of code in terms of efficiency and elegance | ["not at all efficient", "slightly efficient", "moderately efficient", "very efficient", "extremely efficient"] |
| Code Correctness | Correctness of the provided code | ["completely incorrect", "mostly incorrect", "partly correct", "mostly correct", "completely correct"] |
Then, after running QuantifierAgent, we obtained the results presented in Fig. 3, where you can see three models:
- AgentChat
- ReAct
- GPT-4 Vanilla Solver
Lighter colors represent estimates for failed cases, and brighter colors show how discovered criteria were quantified.
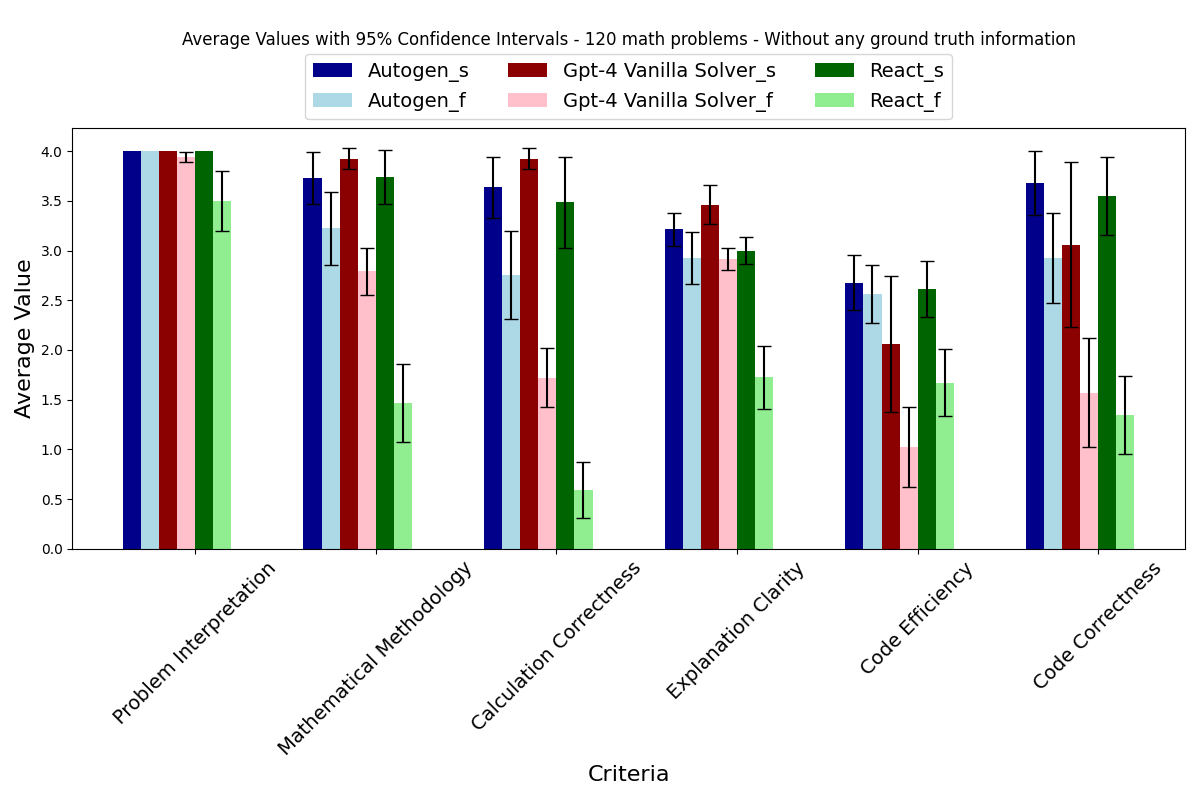
Fig.3 presents results based on overall math problems dataset _s stands for successful cases, _f - stands for failed cases
We note that while applying agentEval to math problems, the agent was not exposed to any ground truth information about the problem. As such, this figure illustrates an estimated performance of the three different agents, namely, Autogen (blue), Gpt-4 (red), and ReAct (green). We observe that by comparing the performance of any of the three agents in successful cases (dark bars of any color) versus unsuccessful cases (lighter version of the same bar), we note that AgentEval was able to assign higher quantification to successful cases than that of failed ones. This observation verifies AgentEval's ability for task utility prediction. Additionally, AgentEval allows us to go beyond just a binary definition of success, enabling a more in-depth comparison between successful and failed cases.
It's important not only to identify what is not working but also to recognize what and why actually went well.
Limitations and Future Work
The current implementation of AgentEval has a number of limitations which are planning to overcome in the future:
- The list of criteria varies per run (unless you store a seed). We would recommend to run
CriticAgentat least two times, and pick criteria you think is important for your domain. - The results of the
QuantifierAgentcan vary with each run, so we recommend conducting multiple runs to observe the extent of result variations.
To mitigate the limitations mentioned above, we are working on VerifierAgent, whose goal is to stabilize the results and provide additional explanations.
Summary
CriticAgent and QuantifierAgent can be applied to the logs of any type of application, providing you with an in-depth understanding of the utility your solution brings to the user for a given task.
We would love to hear about how AgentEval works for your application. Any feedback would be useful for future development. Please contact us on our Discord.
Previous Research
@InProceedings{pmlr-v176-kiseleva22a,
title = "Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021",
author = "Kiseleva, Julia and Li, Ziming and Aliannejadi, Mohammad and Mohanty, Shrestha and ter Hoeve, Maartje and Burtsev, Mikhail and Skrynnik, Alexey and Zholus, Artem and Panov, Aleksandr and Srinet, Kavya and Szlam, Arthur and Sun, Yuxuan and Hofmann, Katja and C{\^o}t{\'e}, Marc-Alexandre and Awadallah, Ahmed and Abdrazakov, Linar and Churin, Igor and Manggala, Putra and Naszadi, Kata and van der Meer, Michiel and Kim, Taewoon",
booktitle = "Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track",
pages = "146--161",
year = 2022,
editor = "Kiela, Douwe and Ciccone, Marco and Caputo, Barbara",
volume = 176,
series = "Proceedings of Machine Learning Research",
month = "06--14 Dec",
publisher = "PMLR",
pdf = {https://proceedings.mlr.press/v176/kiseleva22a/kiseleva22a.pdf},
url = {https://proceedings.mlr.press/v176/kiseleva22a.html}.
}
@InProceedings{pmlr-v220-kiseleva22a,
title = "Interactive Grounded Language Understanding in a Collaborative Environment: Retrospective on Iglu 2022 Competition",
author = "Kiseleva, Julia and Skrynnik, Alexey and Zholus, Artem and Mohanty, Shrestha and Arabzadeh, Negar and C\^{o}t\'e, Marc-Alexandre and Aliannejadi, Mohammad and Teruel, Milagro and Li, Ziming and Burtsev, Mikhail and ter Hoeve, Maartje and Volovikova, Zoya and Panov, Aleksandr and Sun, Yuxuan and Srinet, Kavya and Szlam, Arthur and Awadallah, Ahmed and Rho, Seungeun and Kwon, Taehwan and Wontae Nam, Daniel and Bivort Haiek, Felipe and Zhang, Edwin and Abdrazakov, Linar and Qingyam, Guo and Zhang, Jason and Guo, Zhibin",
booktitle = "Proceedings of the NeurIPS 2022 Competitions Track",
pages = "204--216",
year = 2022,
editor = "Ciccone, Marco and Stolovitzky, Gustavo and Albrecht, Jacob",
volume = 220,
series = "Proceedings of Machine Learning Research",
month = "28 Nov--09 Dec",
publisher = "PMLR",
pdf = "https://proceedings.mlr.press/v220/kiseleva22a/kiseleva22a.pdf",
url = "https://proceedings.mlr.press/v220/kiseleva22a.html".
}