

TL;DR: Introducing AutoBuild, building multi-agent system automatically, fast, and easily for complex tasks with minimal user prompt required, powered by a new designed class AgentBuilder. AgentBuilder also supports open-source LLMs by leveraging vLLM and FastChat. Checkout example notebooks and source code for reference:
Introduction
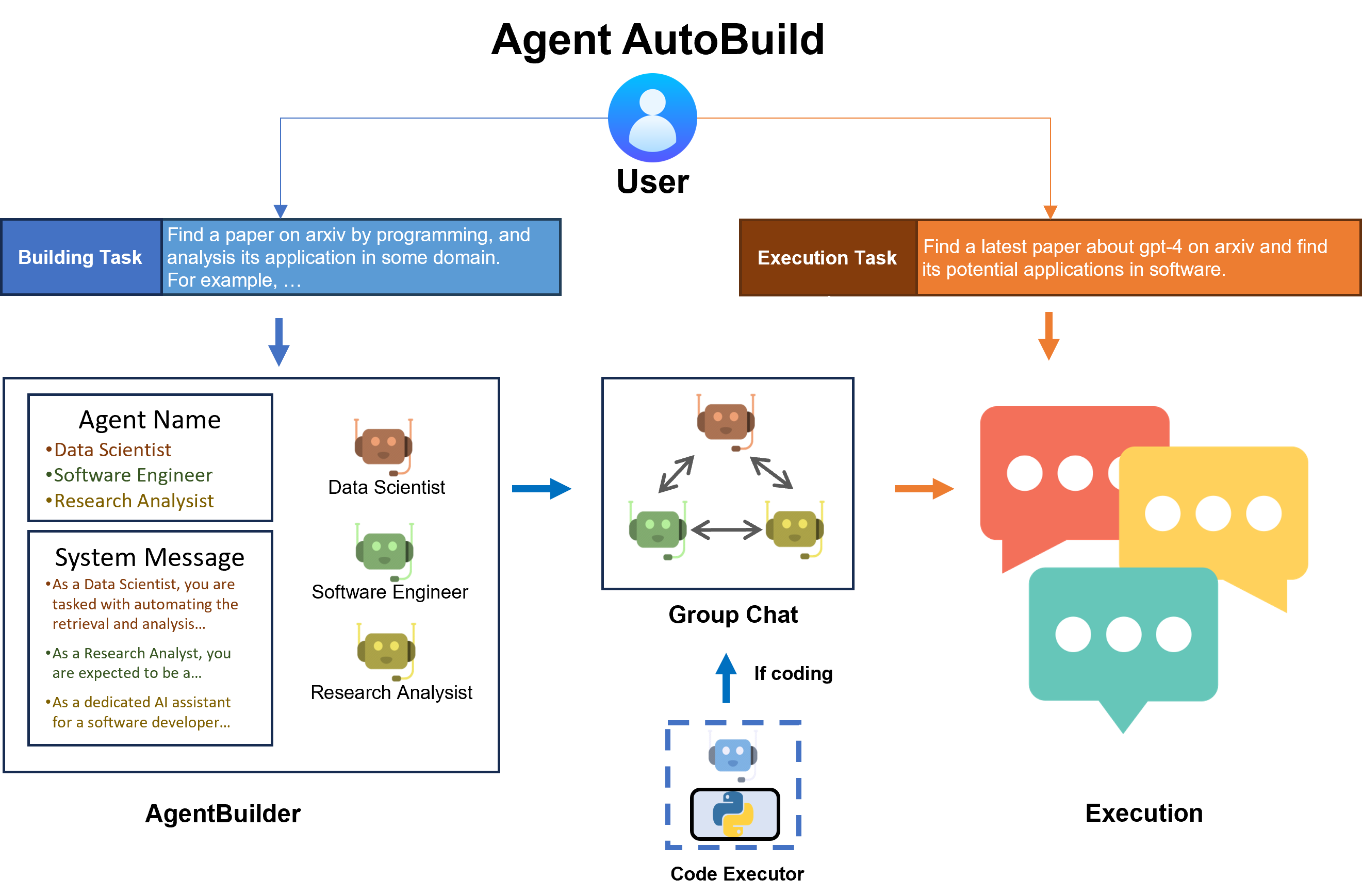
In this blog, we introduce AutoBuild, a pipeline that can automatically build multi-agent systems for complex tasks. Specifically, we design a new class called AgentBuilder, which will complete the generation of participant expert agents and the construction of group chat automatically after the user provides descriptions of a building task and an execution task.
AgentBuilder supports open-source models on Hugging Face powered by vLLM and FastChat. Once the user chooses to use open-source LLM, AgentBuilder will set up an endpoint server automatically without any user participation.
Installation
- AutoGen:
pip install autogen[autobuild]
- (Optional: if you want to use open-source LLMs) vLLM and FastChat
pip install vllm fastchat
Basic Example
In this section, we provide a step-by-step example of how to use AgentBuilder to build a multi-agent system for a specific task.
Step 1: prepare configurations
First, we need to prepare the Agent configurations. Specifically, a config path containing the model name and API key, and a default config for each agent, are required.
config_file_or_env = '/home/elpis_ubuntu/LLM/autogen/OAI_CONFIG_LIST' # modify path
default_llm_config = {
'temperature': 0
}
Step 2: create an AgentBuilder instance
Then, we create an AgentBuilder instance with the config path and default config. You can also specific the builder model and agent model, which are the LLMs used for building and agent respectively.
from autogen.agentchat.contrib.agent_builder import AgentBuilder
builder = AgentBuilder(config_file_or_env=config_file_or_env, builder_model='gpt-4-1106-preview', agent_model='gpt-4-1106-preview')
Step 3: specify the building task
Specify a building task with a general description. Building task will help the build manager (a LLM) decide what agents should be built. Note that your building task should have a general description of the task. Adding some specific examples is better.
building_task = "Find a paper on arxiv by programming, and analyze its application in some domain. For example, find a latest paper about gpt-4 on arxiv and find its potential applications in software."
Step 4: build group chat agents
Use build() to let the build manager (with a builder_model as backbone) complete the group chat agents generation.
If you think coding is necessary for your task, you can use coding=True to add a user proxy (a local code interpreter) into the agent list as:
agent_list, agent_configs = builder.build(building_task, default_llm_config, coding=True)
If coding is not specified, AgentBuilder will determine on its own whether the user proxy should be added or not according to the task.
The generated agent_list is a list of AssistantAgent instances.
If coding is true, a user proxy (a UserProxyAssistant instance) will be added as the first element to the agent_list.
agent_configs is a list of agent configurations including agent name, backbone LLM model, and system message.
For example
// an example of agent_configs. AgentBuilder will generate agents with the following configurations.
[
{
"name": "ArXiv_Data_Scraper_Developer",
"model": "gpt-4-1106-preview",
"system_message": "You are now in a group chat. You need to complete a task with other participants. As an ArXiv_Data_Scraper_Developer, your focus is to create and refine tools capable of intelligent search and data extraction from arXiv, honing in on topics within the realms of computer science and medical science. Utilize your proficiency in Python programming to design scripts that navigate, query, and parse information from the platform, generating valuable insights and datasets for analysis. \n\nDuring your mission, it\u2019s not just about formulating queries; your role encompasses the optimization and precision of the data retrieval process, ensuring relevance and accuracy of the information extracted. If you encounter an issue with a script or a discrepancy in the expected output, you are encouraged to troubleshoot and offer revisions to the code you find in the group chat.\n\nWhen you reach a point where the existing codebase does not fulfill task requirements or if the operation of provided code is unclear, you should ask for help from the group chat manager. They will facilitate your advancement by providing guidance or appointing another participant to assist you. Your ability to adapt and enhance scripts based on peer feedback is critical, as the dynamic nature of data scraping demands ongoing refinement of techniques and approaches.\n\nWrap up your participation by confirming the user's need has been satisfied with the data scraping solutions you've provided. Indicate the completion of your task by replying \"TERMINATE\" in the group chat.",
"description": "ArXiv_Data_Scraper_Developer is a specialized software development role requiring proficiency in Python, including familiarity with web scraping libraries such as BeautifulSoup or Scrapy, and a solid understanding of APIs and data parsing. They must possess the ability to identify and correct errors in existing scripts and confidently engage in technical discussions to improve data retrieval processes. The role also involves a critical eye for troubleshooting and optimizing code to ensure efficient data extraction from the ArXiv platform for research and analysis purposes."
},
...
]
Step 5: execute the task
Let agents generated in build() complete the task collaboratively in a group chat.
import autogen
def start_task(execution_task: str, agent_list: list, llm_config: dict):
config_list = autogen.config_list_from_json(config_file_or_env, filter_dict={"model": ["gpt-4-1106-preview"]})
group_chat = autogen.GroupChat(agents=agent_list, messages=[], max_round=12)
manager = autogen.GroupChatManager(
groupchat=group_chat, llm_config={"config_list": config_list, **llm_config}
)
agent_list[0].initiate_chat(manager, message=execution_task)
start_task(
execution_task="Find a recent paper about gpt-4 on arxiv and find its potential applications in software.",
agent_list=agent_list,
llm_config=default_llm_config
)
Step 6 (Optional): clear all agents and prepare for the next task
You can clear all agents generated in this task by the following code if your task is completed or if the next task is largely different from the current task.
builder.clear_all_agents(recycle_endpoint=True)
If the agent's backbone is an open-source LLM, this process will also shut down the endpoint server. More details are in the next section.
If necessary, you can use recycle_endpoint=False to retain the previous open-source LLM's endpoint server.
Save and Load
You can save all necessary information of the built group chat agents by
saved_path = builder.save()
Configurations will be saved in JSON format with the following content:
// FILENAME: save_config_TASK_MD5.json
{
"building_task": "Find a paper on arxiv by programming, and analysis its application in some domain. For example, find a latest paper about gpt-4 on arxiv and find its potential applications in software.",
"agent_configs": [
{
"name": "...",
"model": "...",
"system_message": "...",
"description": "..."
},
...
],
"manager_system_message": "...",
"code_execution_config": {...},
"default_llm_config": {...}
}
You can provide a specific filename, otherwise, AgentBuilder will save config to the current path with the generated filename save_config_TASK_MD5.json.
You can load the saved config and skip the building process. AgentBuilder will create agents with those information without prompting the build manager.
new_builder = AgentBuilder(config_file_or_env=config_file_or_env)
agent_list, agent_config = new_builder.load(saved_path)
start_task(...) # skip build()
Use OpenAI Assistant
Assistants API allows you to build AI assistants within your own applications.
An Assistant has instructions and can leverage models, tools, and knowledge to respond to user queries.
AutoBuild also supports the assistant API by adding use_oai_assistant=True to build().
# Transfer to the OpenAI Assistant API.
agent_list, agent_config = new_builder.build(building_task, default_llm_config, use_oai_assistant=True)
...
(Experimental) Use Open-source LLM
AutoBuild supports open-source LLM by vLLM and FastChat. Check the supported model list here. After satisfying the requirements, you can add an open-source LLM's huggingface repository to the config file,
// Add the LLM's huggingface repo to your config file and use EMPTY as the api_key.
[
...
{
"model": "meta-llama/Llama-2-13b-chat-hf",
"api_key": "EMPTY"
}
]
and specify it when initializing AgentBuilder. AgentBuilder will automatically set up an endpoint server for open-source LLM. Make sure you have sufficient GPUs resources.
Future work/Roadmap
- Let the builder select the best agents from a given library/database to solve the task.
Summary
We propose AutoBuild with a new class AgentBuilder.
AutoBuild can help user solve their complex task with an automatically built multi-agent system.
AutoBuild supports open-source LLMs and GPTs API, giving users more flexibility to choose their favorite models.
More advanced features are coming soon.