StateFlow: Build Workflows through State-Oriented Actions
![]()
AutoGen offers conversable agents powered by LLM, tool or human, which can be used to perform tasks collectively via automated chat. In this notebook, we introduce how to use groupchat to build workflows with AutoGen agents from a state-oriented perspective.
Install pyautogen:
pip install pyautogen
For more information, please refer to the installation guide.
Set your API Endpoint
The
config_list_from_json
function loads a list of configurations from an environment variable or
a json file.
import autogen
config_list = autogen.config_list_from_json(
"OAI_CONFIG_LIST",
filter_dict={
"tags": ["gpt-4", "gpt-4-32k"],
},
)
Learn more about configuring LLMs for agents here.
A workflow for research
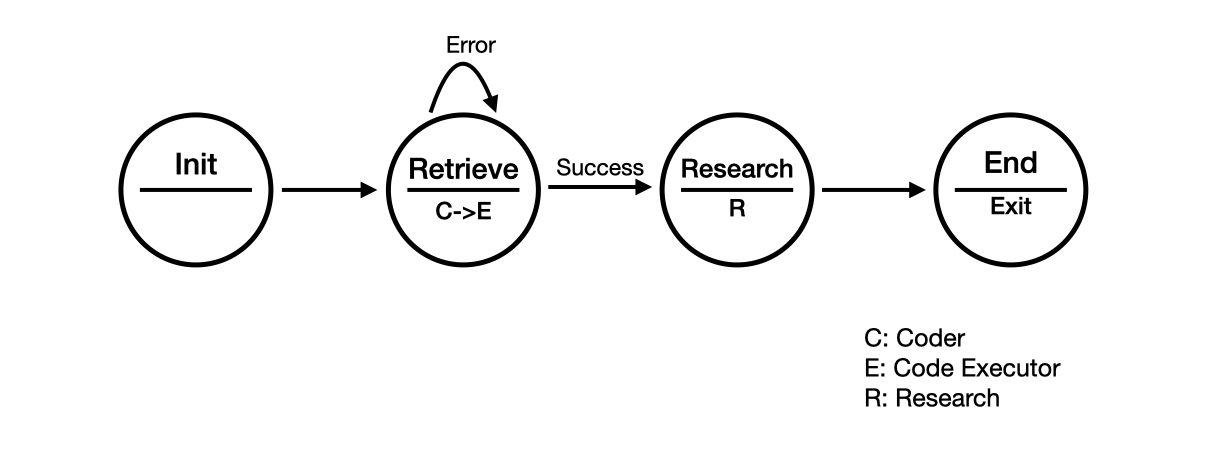
We define the following agents: - Initializer: Start the workflow by sending a task. - Coder: Retrieve papers from the internet by writing code. - Executor: Execute the code. - Scientist: Read the papers and write a summary.
In the Figure, we define a simple workflow for research with 4 states: Init, Retrieve, Research and End. Within each state, we will call different agents to perform the tasks. - Init: We use the initializer to start the workflow. - Retrieve: We will first call the coder to write code and then call the executor to execute the code. - Research: We will call the scientist to read the papers and write a summary. - End: We will end the workflow.
Through customizing the speaker selection method, we can easily realize the state-oriented workflow by defining the transitions between different agents.
import tempfile
from autogen.coding import LocalCommandLineCodeExecutor
temp_dir = tempfile.TemporaryDirectory()
executor = LocalCommandLineCodeExecutor(
timeout=10, # Timeout for each code execution in seconds.
work_dir=temp_dir.name, # Use the temporary directory to store the code files.
)
gpt4_config = {
"cache_seed": False, # change the cache_seed for different trials
"temperature": 0,
"config_list": config_list,
"timeout": 120,
}
initializer = autogen.UserProxyAgent(
name="Init",
code_execution_config=False,
)
coder = autogen.AssistantAgent(
name="Retrieve_Action_1",
llm_config=gpt4_config,
system_message="""You are the Coder. Given a topic, write code to retrieve related papers from the arXiv API, print their title, authors, abstract, and link.
You write python/shell code to solve tasks. Wrap the code in a code block that specifies the script type. The user can't modify your code. So do not suggest incomplete code which requires others to modify. Don't use a code block if it's not intended to be executed by the executor.
Don't include multiple code blocks in one response. Do not ask others to copy and paste the result. Check the execution result returned by the executor.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
""",
)
executor = autogen.UserProxyAgent(
name="Retrieve_Action_2",
system_message="Executor. Execute the code written by the Coder and report the result.",
human_input_mode="NEVER",
code_execution_config={"executor": executor},
)
scientist = autogen.AssistantAgent(
name="Research_Action_1",
llm_config=gpt4_config,
system_message="""You are the Scientist. Please categorize papers after seeing their abstracts printed and create a markdown table with Domain, Title, Authors, Summary and Link""",
)
def state_transition(last_speaker, groupchat):
messages = groupchat.messages
if last_speaker is initializer:
# init -> retrieve
return coder
elif last_speaker is coder:
# retrieve: action 1 -> action 2
return executor
elif last_speaker is executor:
if messages[-1]["content"] == "exitcode: 1":
# retrieve --(execution failed)--> retrieve
return coder
else:
# retrieve --(execution sucess)--> research
return scientist
elif last_speaker == "Scientist":
# research -> end
return None
groupchat = autogen.GroupChat(
agents=[initializer, coder, executor, scientist],
messages=[],
max_round=20,
speaker_selection_method=state_transition,
)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=gpt4_config)
chat_result = initializer.initiate_chat(
manager, message="Topic: LLM applications papers from last week. Requirement: 5 - 10 papers from different domains."
)
Topic: LLM applications papers from last week. Requirement: 5 - 10 papers from different domains.
--------------------------------------------------------------------------------
To retrieve related papers from the arXiv API, we can use Python with the `requests` library to send a query to the API and parse the response. Below is a Python script that searches for papers related to "LLM applications" (Large Language Models applications) from the last week, across different domains, and prints out the required information for 5 to 10 papers.
```python
import requests
from datetime import datetime, timedelta
import feedparser
# Define the base URL for the arXiv API
ARXIV_API_URL = "http://export.arxiv.org/api/query?"
# Define the search parameters
search_query = "all:\"LLM applications\""
start = 0
max_results = 10
sort_by = "submittedDate"
sort_order = "descending"
# Calculate the date one week ago from today
one_week_ago = (datetime.now() - timedelta(days=7)).strftime('%Y-%m-%dT%H:%M:%SZ')
# Construct the query
query = f"search_query={search_query}&start={start}&max_results={max_results}&sortBy={sort_by}&sortOrder={sort_order}&submittedDateRange={one_week_ago}-"
# Send the request to the arXiv API
response = requests.get(ARXIV_API_URL + query)
# Parse the response using feedparser
feed = feedparser.parse(response.content)
# Print the title, authors, abstract, and link of each paper
for entry in feed.entries:
print("Title:", entry.title)
print("Authors:", ', '.join(author.name for author in entry.authors))
print("Abstract:", entry.summary)
print("Link:", entry.link)
print("\n---\n")
```
This script will print the title, authors, abstract, and link for each paper related to "LLM applications" that was submitted in the last week, up to a maximum of 10 papers. If you want to ensure that the papers are from different domains, you might need to manually check the categories of the papers or refine the search query to target specific domains.
--------------------------------------------------------------------------------
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 0 (execution succeeded)
Code output: Title: Adapting LLMs for Efficient Context Processing through Soft Prompt
Compression
Authors: Cangqing Wang, Yutian Yang, Ruisi Li, Dan Sun, Ruicong Cai, Yuzhu Zhang, Chengqian Fu, Lillian Floyd
Abstract: The rapid advancement of Large Language Models (LLMs) has inaugurated a
transformative epoch in natural language processing, fostering unprecedented
proficiency in text generation, comprehension, and contextual scrutiny.
Nevertheless, effectively handling extensive contexts, crucial for myriad
applications, poses a formidable obstacle owing to the intrinsic constraints of
the models' context window sizes and the computational burdens entailed by
their operations. This investigation presents an innovative framework that
strategically tailors LLMs for streamlined context processing by harnessing the
synergies among natural language summarization, soft prompt compression, and
augmented utility preservation mechanisms. Our methodology, dubbed
SoftPromptComp, amalgamates natural language prompts extracted from
summarization methodologies with dynamically generated soft prompts to forge a
concise yet semantically robust depiction of protracted contexts. This
depiction undergoes further refinement via a weighting mechanism optimizing
information retention and utility for subsequent tasks. We substantiate that
our framework markedly diminishes computational overhead and enhances LLMs'
efficacy across various benchmarks, while upholding or even augmenting the
caliber of the produced content. By amalgamating soft prompt compression with
sophisticated summarization, SoftPromptComp confronts the dual challenges of
managing lengthy contexts and ensuring model scalability. Our findings point
towards a propitious trajectory for augmenting LLMs' applicability and
efficiency, rendering them more versatile and pragmatic for real-world
applications. This research enriches the ongoing discourse on optimizing
language models, providing insights into the potency of soft prompts and
summarization techniques as pivotal instruments for the forthcoming generation
of NLP solutions.
Link: http://arxiv.org/abs/2404.04997v1
---
Title: Explainable Traffic Flow Prediction with Large Language Models
Authors: Xusen Guo, Qiming Zhang, Mingxing Peng, Meixin Zhu, Hao, Yang
Abstract: Traffic flow prediction is crucial for urban planning, transportation
management, and infrastructure development. However, achieving both accuracy
and interpretability in prediction models remains challenging due to the
complexity of traffic data and the inherent opacity of deep learning
methodologies. In this paper, we propose a novel approach, Traffic Flow
Prediction LLM (TF-LLM), which leverages large language models (LLMs) to
generate interpretable traffic flow predictions. By transferring multi-modal
traffic data into natural language descriptions, TF-LLM captures complex
spatial-temporal patterns and external factors such as weather conditions,
Points of Interest (PoIs), date, and holidays. We fine-tune the LLM framework
using language-based instructions to align with spatial-temporal traffic flow
data. Our comprehensive multi-modal traffic flow dataset (CATraffic) in
California enables the evaluation of TF-LLM against state-of-the-art deep
learning baselines. Results demonstrate TF-LLM's competitive accuracy while
providing intuitive and interpretable predictions. We discuss the
spatial-temporal and input dependencies for explainable future flow
forecasting, showcasing TF-LLM's potential for diverse city prediction tasks.
This paper contributes to advancing explainable traffic prediction models and
lays a foundation for future exploration of LLM applications in transportation.
Link: http://arxiv.org/abs/2404.02937v2
---
Title: Designing Child-Centric AI Learning Environments: Insights from
LLM-Enhanced Creative Project-Based Learning
Authors: Siyu Zha, Yuehan Qiao, Qingyu Hu, Zhongsheng Li, Jiangtao Gong, Yingqing Xu
Abstract: Project-based learning (PBL) is an instructional method that is very helpful
in nurturing students' creativity, but it requires significant time and energy
from both students and teachers. Large language models (LLMs) have been proven
to assist in creative tasks, yet much controversy exists regarding their role
in fostering creativity. This paper explores the potential of LLMs in PBL
settings, with a special focus on fostering creativity. We began with an
exploratory study involving 12 middle school students and identified five
design considerations for LLM applications in PBL. Building on this, we
developed an LLM-empowered, 48-hour PBL program and conducted an instructional
experiment with 31 middle school students. Our results indicated that LLMs can
enhance every stage of PBL. Additionally, we also discovered ambivalent
perspectives among students and mentors toward LLM usage. Furthermore, we
explored the challenge and design implications of integrating LLMs into PBL and
reflected on the program. By bridging AI advancements into educational
practice, our work aims to inspire further discourse and investigation into
harnessing AI's potential in child-centric educational settings.
Link: http://arxiv.org/abs/2403.16159v2
---
Title: The opportunities and risks of large language models in mental health
Authors: Hannah R. Lawrence, Renee A. Schneider, Susan B. Rubin, Maja J. Mataric, Daniel J. McDuff, Megan Jones Bell
Abstract: Global rates of mental health concerns are rising and there is increasing
realization that existing models of mental healthcare will not adequately
expand to meet the demand. With the emergence of large language models (LLMs)
has come great optimism regarding their promise to create novel, large-scale
solutions to support mental health. Despite their nascence, LLMs have already
been applied to mental health-related tasks. In this review, we summarize the
extant literature on efforts to use LLMs to provide mental health education,
assessment, and intervention and highlight key opportunities for positive
impact in each area. We then highlight risks associated with LLMs application
to mental health and encourage adoption of strategies to mitigate these risks.
The urgent need for mental health support must be balanced with responsible
development, testing, and deployment of mental health LLMs. Especially critical
is ensuring that mental health LLMs are fine-tuned for mental health, enhance
mental health equity, adhere to ethical standards, and that people, including
those with lived experience with mental health concerns, are involved in all
stages from development through deployment. Prioritizing these efforts will
minimize potential harms to mental health and maximize the likelihood that LLMs
will positively impact mental health globally.
Link: http://arxiv.org/abs/2403.14814v2
---
Title: Large Language Models for Blockchain Security: A Systematic Literature
Review
Authors: Zheyuan He, Zihao Li, Sen Yang
Abstract: Large Language Models (LLMs) have emerged as powerful tools in various
domains involving blockchain security (BS). Several recent studies are
exploring LLMs applied to BS. However, there remains a gap in our understanding
regarding the full scope of applications, impacts, and potential constraints of
LLMs on blockchain security. To fill this gap, we conduct a literature review
on LLM4BS.
As the first review of LLM's application on blockchain security, our study
aims to comprehensively analyze existing research and elucidate how LLMs
contribute to enhancing the security of blockchain systems. Through a thorough
examination of scholarly works, we delve into the integration of LLMs into
various aspects of blockchain security. We explore the mechanisms through which
LLMs can bolster blockchain security, including their applications in smart
contract auditing, identity verification, anomaly detection, vulnerable repair,
and so on. Furthermore, we critically assess the challenges and limitations
associated with leveraging LLMs for blockchain security, considering factors
such as scalability, privacy concerns, and adversarial attacks. Our review
sheds light on the opportunities and potential risks inherent in this
convergence, providing valuable insights for researchers, practitioners, and
policymakers alike.
Link: http://arxiv.org/abs/2403.14280v2
---
Title: Do Large Language Model Understand Multi-Intent Spoken Language ?
Authors: Shangjian Yin, Peijie Huang, Yuhong Xu, Haojing Huang, Jiatian Chen
Abstract: This study marks a significant advancement by harnessing Large Language
Models (LLMs) for multi-intent spoken language understanding (SLU), proposing a
unique methodology that capitalizes on the generative power of LLMs within an
SLU context. Our innovative technique reconfigures entity slots specifically
for LLM application in multi-intent SLU environments and introduces the concept
of Sub-Intent Instruction (SII), enhancing the dissection and interpretation of
intricate, multi-intent communication within varied domains. The resultant
datasets, dubbed LM-MixATIS and LM-MixSNIPS, are crafted from pre-existing
benchmarks. Our research illustrates that LLMs can match and potentially excel
beyond the capabilities of current state-of-the-art multi-intent SLU models. It
further explores LLM efficacy across various intent configurations and dataset
proportions. Moreover, we introduce two pioneering metrics, Entity Slot
Accuracy (ESA) and Combined Semantic Accuracy (CSA), to provide an in-depth
analysis of LLM proficiency in this complex field.
Link: http://arxiv.org/abs/2403.04481v2
---
Title: Breaking the Language Barrier: Can Direct Inference Outperform
Pre-Translation in Multilingual LLM Applications?
Authors: Yotam Intrator, Matan Halfon, Roman Goldenberg, Reut Tsarfaty, Matan Eyal, Ehud Rivlin, Yossi Matias, Natalia Aizenberg
Abstract: Large language models hold significant promise in multilingual applications.
However, inherent biases stemming from predominantly English-centric
pre-training have led to the widespread practice of pre-translation, i.e.,
translating non-English inputs to English before inference, leading to
complexity and information loss. This study re-evaluates the need for
pre-translation in the context of PaLM2 models (Anil et al., 2023), which have
been established as highly performant in multilingual tasks. We offer a
comprehensive investigation across 108 languages and 6 diverse benchmarks,
including open-end generative tasks, which were excluded from previous similar
studies. Our findings challenge the pre-translation paradigm established in
prior research, highlighting the advantages of direct inference in PaLM2.
Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108
languages. These findings pave the way for more efficient and effective
multilingual applications, alleviating the limitations associated with
pre-translation and unlocking linguistic authenticity.
Link: http://arxiv.org/abs/2403.04792v1
---
Title: SciAssess: Benchmarking LLM Proficiency in Scientific Literature
Analysis
Authors: Hengxing Cai, Xiaochen Cai, Junhan Chang, Sihang Li, Lin Yao, Changxin Wang, Zhifeng Gao, Hongshuai Wang, Yongge Li, Mujie Lin, Shuwen Yang, Jiankun Wang, Yuqi Yin, Yaqi Li, Linfeng Zhang, Guolin Ke
Abstract: Recent breakthroughs in Large Language Models (LLMs) have revolutionized
natural language understanding and generation, igniting a surge of interest in
leveraging these technologies in the field of scientific literature analysis.
Existing benchmarks, however, inadequately evaluate the proficiency of LLMs in
scientific literature analysis, especially in scenarios involving complex
comprehension and multimodal data. In response, we introduced SciAssess, a
benchmark tailored for the in-depth analysis of scientific literature, crafted
to provide a thorough assessment of LLMs' efficacy. SciAssess focuses on
evaluating LLMs' abilities in memorization, comprehension, and analysis within
the context of scientific literature analysis. It includes representative tasks
from diverse scientific fields, such as general chemistry, organic materials,
and alloy materials. And rigorous quality control measures ensure its
reliability in terms of correctness, anonymization, and copyright compliance.
SciAssess evaluates leading LLMs, including GPT-4, GPT-3.5, and Gemini,
identifying their strengths and aspects for improvement and supporting the
ongoing development of LLM applications in scientific literature analysis.
SciAssess and its resources are made available at https://sci-assess.github.io,
offering a valuable tool for advancing LLM capabilities in scientific
literature analysis.
Link: http://arxiv.org/abs/2403.01976v2
---
Title: Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Authors: Chulin Xie, Zinan Lin, Arturs Backurs, Sivakanth Gopi, Da Yu, Huseyin A Inan, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, Bo Li, Sergey Yekhanin
Abstract: Text data has become extremely valuable due to the emergence of machine
learning algorithms that learn from it. A lot of high-quality text data
generated in the real world is private and therefore cannot be shared or used
freely due to privacy concerns. Generating synthetic replicas of private text
data with a formal privacy guarantee, i.e., differential privacy (DP), offers a
promising and scalable solution. However, existing methods necessitate DP
finetuning of large language models (LLMs) on private data to generate DP
synthetic data. This approach is not viable for proprietary LLMs (e.g.,
GPT-3.5) and also demands considerable computational resources for open-source
LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE)
algorithm to generate DP synthetic images with only API access to diffusion
models. In this work, we propose an augmented PE algorithm, named Aug-PE, that
applies to the complex setting of text. We use API access to an LLM and
generate DP synthetic text without any model training. We conduct comprehensive
experiments on three benchmark datasets. Our results demonstrate that Aug-PE
produces DP synthetic text that yields competitive utility with the SOTA DP
finetuning baselines. This underscores the feasibility of relying solely on API
access of LLMs to produce high-quality DP synthetic texts, thereby facilitating
more accessible routes to privacy-preserving LLM applications. Our code and
data are available at https://github.com/AI-secure/aug-pe.
Link: http://arxiv.org/abs/2403.01749v1
---
Title: SERVAL: Synergy Learning between Vertical Models and LLMs towards
Oracle-Level Zero-shot Medical Prediction
Authors: Jiahuan Yan, Jintai Chen, Chaowen Hu, Bo Zheng, Yaojun Hu, Jimeng Sun, Jian Wu
Abstract: Recent development of large language models (LLMs) has exhibited impressive
zero-shot proficiency on generic and common sense questions. However, LLMs'
application on domain-specific vertical questions still lags behind, primarily
due to the humiliation problems and deficiencies in vertical knowledge.
Furthermore, the vertical data annotation process often requires
labor-intensive expert involvement, thereby presenting an additional challenge
in enhancing the model's vertical capabilities. In this paper, we propose
SERVAL, a synergy learning pipeline designed for unsupervised development of
vertical capabilities in both LLMs and small models by mutual enhancement.
Specifically, SERVAL utilizes the LLM's zero-shot outputs as annotations,
leveraging its confidence to teach a robust vertical model from scratch.
Reversely, the trained vertical model guides the LLM fine-tuning to enhance its
zero-shot capability, progressively improving both models through an iterative
process. In medical domain, known for complex vertical knowledge and costly
annotations, comprehensive experiments show that, without access to any gold
labels, SERVAL with the synergy learning of OpenAI GPT-3.5 and a simple model
attains fully-supervised competitive performance across ten widely used medical
datasets. These datasets represent vertically specialized medical diagnostic
scenarios (e.g., diabetes, heart diseases, COVID-19), highlighting the
potential of SERVAL in refining the vertical capabilities of LLMs and training
vertical models from scratch, all achieved without the need for annotations.
Link: http://arxiv.org/abs/2403.01570v2
---
--------------------------------------------------------------------------------
Based on the provided code output, here is a markdown table categorizing the papers by domain, along with their titles, authors, summaries, and links:
| Domain | Title | Authors | Summary | Link |
|--------|-------|---------|---------|------|
| Natural Language Processing | Adapting LLMs for Efficient Context Processing through Soft Prompt Compression | Cangqing Wang, et al. | The paper presents a framework for efficient context processing in LLMs using natural language summarization and soft prompt compression. | [Link](http://arxiv.org/abs/2404.04997v1) |
| Transportation | Explainable Traffic Flow Prediction with Large Language Models | Xusen Guo, et al. | This paper introduces a novel approach for interpretable traffic flow predictions using LLMs, which captures complex spatial-temporal patterns. | [Link](http://arxiv.org/abs/2404.02937v2) |
| Education | Designing Child-Centric AI Learning Environments: Insights from LLM-Enhanced Creative Project-Based Learning | Siyu Zha, et al. | The study explores the potential of LLMs in enhancing project-based learning (PBL) and fostering creativity in educational settings. | [Link](http://arxiv.org/abs/2403.16159v2) |
| Mental Health | The opportunities and risks of large language models in mental health | Hannah R. Lawrence, et al. | This review summarizes the literature on LLMs in mental health education, assessment, and intervention, highlighting opportunities and risks. | [Link](http://arxiv.org/abs/2403.14814v2) |
| Blockchain Security | Large Language Models for Blockchain Security: A Systematic Literature Review | Zheyuan He, et al. | The paper reviews the application of LLMs in blockchain security, discussing their impact and potential limitations. | [Link](http://arxiv.org/abs/2403.14280v2) |
| Spoken Language Understanding | Do Large Language Model Understand Multi-Intent Spoken Language? | Shangjian Yin, et al. | The study investigates LLMs' capabilities in multi-intent spoken language understanding and proposes new methodologies and metrics. | [Link](http://arxiv.org/abs/2403.04481v2) |
| Multilingualism | Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications? | Yotam Intrator, et al. | The paper challenges the pre-translation paradigm in multilingual LLM applications, showing the advantages of direct inference. | [Link](http://arxiv.org/abs/2403.04792v1) |
| Scientific Literature | SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis | Hengxing Cai, et al. | Introduces SciAssess, a benchmark for evaluating LLMs' abilities in scientific literature analysis across various scientific fields. | [Link](http://arxiv.org/abs/2403.01976v2) |
| Privacy & Security | Differentially Private Synthetic Data via Foundation Model APIs 2: Text | Chulin Xie, et al. | The paper proposes a method to generate differentially private synthetic text data using API access to LLMs without model training. | [Link](http://arxiv.org/abs/2403.01749v1) |
| Medical Diagnostics | SERVAL: Synergy Learning between Vertical Models and LLMs towards Oracle-Level Zero-shot Medical Prediction | Jiahuan Yan, et al. | SERVAL is a synergy learning pipeline that enhances the vertical capabilities of LLMs and trains vertical models without annotations in the medical domain. | [Link](http://arxiv.org/abs/2403.01570v2) |
Please note that the domains have been inferred from the summaries and titles of the papers and may not perfectly reflect the authors' intended categorization.
--------------------------------------------------------------------------------