




TL;DR:
- We introduce ReasoningAgent, an AG2 agent that implements tree-of-thought reasoning with beam search to solve complex problems.
- ReasoningAgent explores multiple reasoning paths in parallel and uses a grader agent to evaluate and select the most promising paths.
- The exploration trajectory and thought tree can be saved locally for further analysis. These logs can even be saved as SFT dataset and preference dataset for DPO and PPO training.
Introduction
Large language models (LLMs) have shown impressive capabilities in various tasks, but they can still struggle with complex reasoning problems that require exploring multiple solution paths. To address this limitation, we introduce ReasoningAgent, an AG2 agent that implements tree-of-thought reasoning with beam search.
The key idea behind ReasoningAgent is to:
- Generate multiple possible reasoning steps at each point
- Evaluate these steps using a grader agent
- Keep track of the most promising paths using beam search
- Continue exploring those paths while pruning less promising ones
This approach allows the agent to systematically explore different reasoning strategies while managing computational resources efficiently.
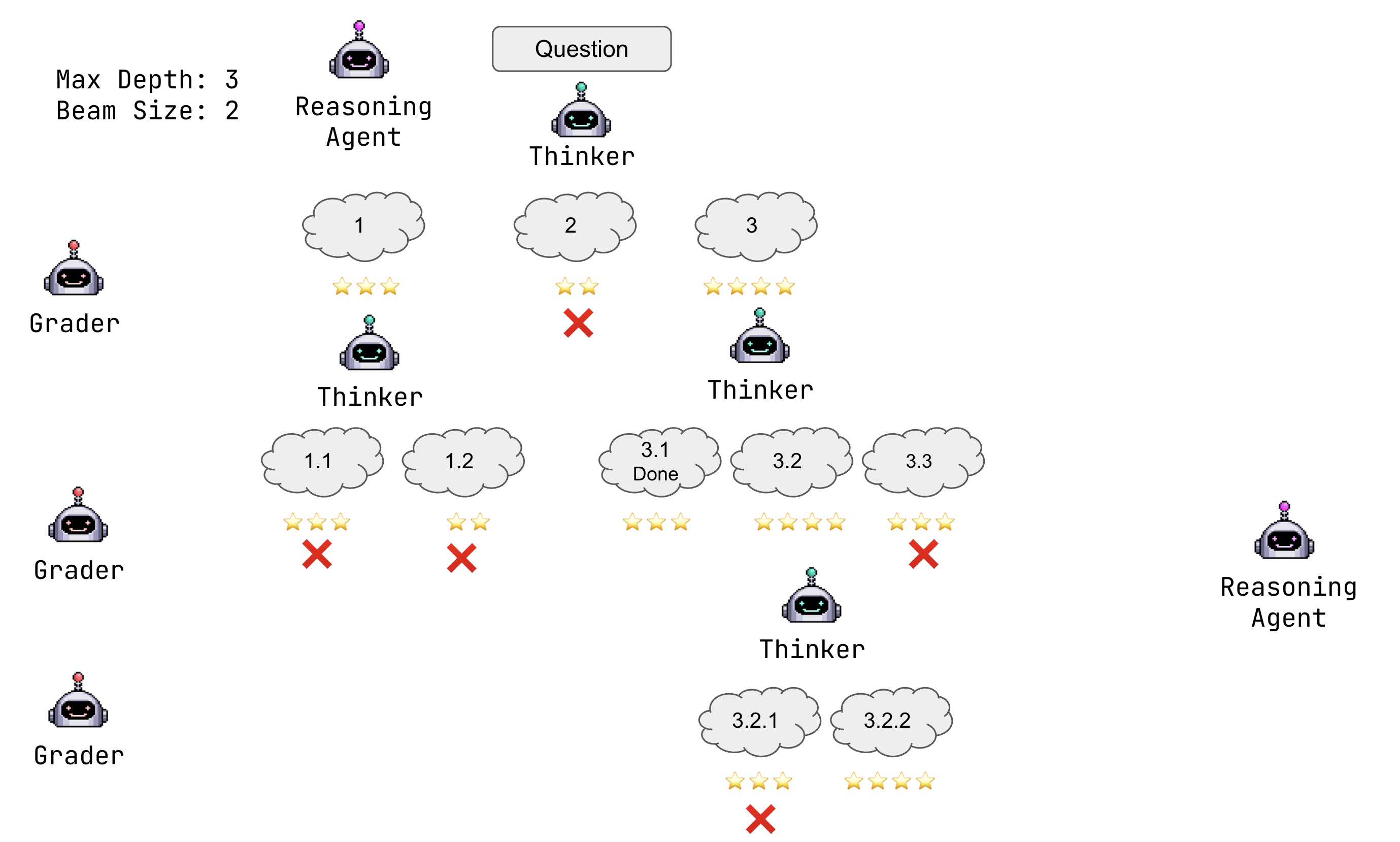
How ReasoningAgent Works
ReasoningAgent consists of three main components:
- A Thinker Agent: Generates possible next steps in the reasoning process
- A Grader Agent: Evaluates the quality of different reasoning paths
- Beam Search: Maintains a fixed number of most promising paths
The process works as follows:
- The thinker agent generates multiple possible next steps from the current state
- The grader agent evaluates each path and assigns a score
- Beam search selects the top-k paths based on these scores
- The process repeats until a solution is found or maximum depth is reached

O1-Style Reasoning with Beam Size 1
When beam_size=1, ReasoningAgent behaves similarly to Chain-of-Thought (CoT) or O1-style reasoning, where only a single reasoning path is explored. This is useful for:
- Simple Problems: When the problem is straightforward and multiple solution paths are unnecessary
- Resource Conservation: When you want to minimize API calls and computational costs
- Baseline Comparison: To compare performance with and without beam search
For example:
# Create a reasoning agent with beam size 1 (O1-style)
reason_agent = ReasoningAgent(
name="reason_agent",
llm_config={"config_list": config_list},
verbose=False,
beam_size=1, # Using beam size 1 for O1-style reasoning
max_depth=3,
)
This configuration means:
- Only one path is explored at each step
- The grader still evaluates the path, but no comparison between paths is needed
- The process is more streamlined but may miss alternative solutions
Here's a simple example of using ReasoningAgent:
import os
from autogen import AssistantAgent, UserProxyAgent
from autogen.agentchat.contrib.reasoning_agent import ReasoningAgent, visualize_tree
# Configure the model
config_list = [{"model": "gpt-4", "api_key": os.environ.get("OPENAI_API_KEY")}]
# Create a reasoning agent with beam search
reasoning_agent = ReasoningAgent(
name="reason_agent",
llm_config={"config_list": config_list},
verbose=False,
beam_size=1, # Using beam size 1 for O1-style reasoning
max_depth=3,
)
# Create a user proxy agent
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
code_execution_config={"use_docker": False},
max_consecutive_auto_reply=10,
)
question = "What is the expected maximum dice value if you can roll a 6-sided dice three times?"
user_proxy.initiate_chat(reasoning_agent, message=question)
Larger Beam Size for Complex Problems
For more complex problems, we can increase the beam size to explore multiple reasoning paths in parallel:
def last_meaningful_msg(sender, recipient, summary_args):
"""
This can be modified based on your required summary method.
"""
import warnings
if sender == recipient:
return "TERMINATE"
summary = ""
chat_messages = recipient.chat_messages[sender]
for msg in reversed(chat_messages):
try:
content = msg["content"]
if isinstance(content, str):
summary = content.replace("TERMINATE", "")
elif isinstance(content, list):
# Remove the `TERMINATE` word in the content list.
summary = "\n".join(
x["text"].replace("TERMINATE", "") for x in content if isinstance(x, dict) and "text" in x
)
if summary.strip().rstrip():
return summary
except (IndexError, AttributeError) as e:
warnings.warn(f"Cannot extract summary using last_msg: {e}. Using an empty str as summary.", UserWarning)
return summary
reason_agent = ReasoningAgent(
name="reason_agent",
llm_config={"config_list": config_list},
verbose=False,
beam_size=3, # Explore 3 paths in parallel
max_depth=3,
)
# Example complex problem
task = "Design a mixed integer linear program for a coffee roasting supply chain"
response = user_proxy.initiate_chat(
reason_agent,
message=task,
summary_method=last_meaningful_msg # can be default i.e., "last_msg"
)
The agent will explore multiple approaches simultaneously:
- Formulating the objective function
- Defining decision variables
- Establishing constraints
Visualizing the Reasoning Process
ReasoningAgent includes built-in visualization support using graphviz:
# After running a query, visualize the reasoning tree
visualize_tree(reason_agent._root)
This generates a tree diagram showing:
- Different reasoning paths explored
- Evaluation scores for each path
- Number of visits to each node
Save the Thought Tree as Training dataset
As you have played with the ReasoningAgent, you may find the LLM's API expense is really high.
On the other hand, the thought tree is a good training dataset for SFT, DPO, and PPO.
After asking a question to the ReasoningAgent, you only need to simply call the to_dict function to save the thought tree as a file.
import json
data = reasoning_agent._root.to_dict()
with open("reasoning_tree.json", "w") as f:
json.dump(data, f)
# recover the node
new_node = ThinkNode.from_dict(json.load(open("reasoning_tree.json", "r")))
You can also use pickle directly to save the thought tree.
import pickle
pickle.dump(reasoning_agent._root, open("reasoning_tree.pkl", "wb"))
# recover the node
new_node = pickle.load(open("reasoning_tree.pkl", "rb"))
Cleaning for SFT
This step finds the best trajectory in the thought tree and converts it to a SFT dataset as a sequence of strings. The best trajectory is determined by following the highest-scoring path from root to leaf.
def extract_sft_dataset(root):
"""
Extract the best trajectory or multiple equally good trajectories
for SFT training.
Args:
root: The root node of the tree.
Returns:
List of best trajectories, where each trajectory is a pair of instruction and response.
"""
instruction = root.content
idx = len("# Question: ") + len(root.content) + 1
def find_leaf_nodes(node):
"""Recursively find all leaf nodes."""
if not node.children:
return [node]
leafs = []
for child in node.children:
leafs.extend(find_leaf_nodes(child))
return leafs
# Step 1: Find all leaf nodes
leaf_nodes = find_leaf_nodes(root)
# Step 2: Determine the highest score among leaf nodes
max_value = max(leaf_nodes, key=lambda x: x.value).value
# Step 3: Collect all leaf nodes with the highest score
best_leafs = [leaf for leaf in leaf_nodes if leaf.value == max_value]
# Step 4: Collect trajectories for all the best leaf nodes
best_trajectories = [{"instruction": instruction, "response": leaf.trajectory[idx:]} for leaf in best_leafs]
return best_trajectories
# Example usage
sft_data = extract_sft_dataset(reason_agent._root)
json.dump(sft_data, open("sft_data.json", "w"), indent=2)
Cleaning for RLHF (DPO and PPO)
This step generates preference pairs by comparing sibling nodes in the tree. For each parent node with multiple children, we create training pairs where the higher-scored response is marked as preferred over the lower-scored one.
def extract_rlhf_preference_dataset(root, contrastive_threshold=0.2):
"""
Extract and generate preference pairs for RLHF training by comparing sibling nodes.
Args:
root: The root node of the tree.
contrastive_threshold (float): between (0, 1), a distance measure that we are confidence to call
one is positive and another is negative.
Returns:
A list of preference pairs, where each pair contains two responses and
indicates which one is preferred.
"""
preference_pairs = []
assert contrastive_threshold > 0
assert contrastive_threshold < 1
def traverse_tree(node):
"""Traverse the tree to compare sibling nodes and collect preferences."""
if not node.children:
return # Leaf node, no comparisons needed
# Step 1: Compare all sibling nodes
for i in range(len(node.children)):
for j in range(len(node.children)):
if i == j:
continue
child_a, child_b = node.children[i], node.children[j]
if child_a.value - child_b.value > contrastive_threshold:
preference_pairs.append({
"instruction": node.trajectory,
"preferred_response": f"Step {child_a.depth}: {child_a.content}",
"dispreferred_response": f"Step {child_b.depth}: {child_b.content}",
})
# Step 2: Recurse into child nodes
for child in node.children:
traverse_tree(child)
# Start traversal from the root
traverse_tree(root)
return preference_pairs
# Example usage
rlhf_data = extract_rlhf_preference_dataset(reason_agent._root)
print(f"There are {len(rlhf_data)} pairs of data\n\n")
json.dump(rlhf_data, open("rlhf_data.json", "w"), indent=2)
The resulting datasets can be used to:
- Fine-tune a base model using SFT with the best trajectories
- Train reward models or directly optimize policies using the preference pairs
- Analyze and improve the reasoning patterns of the agent
Key Benefits
-
Systematic Exploration: Instead of committing to a single reasoning path, ReasoningAgent explores multiple possibilities systematically.
-
Quality Control: The grader agent helps ensure that each step in the reasoning process is sound.
-
Transparency: The visualization tools help understand how the agent arrives at its conclusions.
Conclusion
ReasoningAgent demonstrates how combining tree-of-thought reasoning with beam search can enhance an LLM's problem-solving capabilities. By systematically exploring and evaluating multiple solution paths, it can tackle complex problems more effectively than traditional approaches.
The implementation is flexible and can be customized for different types of problems by adjusting parameters like beam size and maximum depth. We encourage the community to experiment with ReasoningAgent and contribute to its development.
For Further Reading
- Documentation about ReasoningAgent
- Example notebook
- The Original research paper about Tree of Thoughts from Google DeepMind and Princeton University.
Do you have interesting use cases for ReasoningAgent? Would you like to see more features or improvements? Please join our Discord server for discussion.